Leaving Community
Are you sure you want to leave this community? Leaving the community will revoke any permissions you have been granted in this community.
General Help/FAQ
Table of Contents
General
- An overview of the ODC-SCI
- Why share data with the ODC-SCI?
- What are the different account types on the ODC-SCI?
- Why is there a need for all the different account types?
- How does privacy and data protection work on the ODC-SCI?
- What is FAIR data?
- Is there a data quality check process?
Data Upload
- Who can upload data on ODC-SCI?
- What type of data is accepted?
- Should I upload and publish raw data or analyzed data?
- Do I have to format my data for upload?
- ODC data structure: Tidy data format
- What is a Data Dictionary?
- What is a CSV file format?
- Common errors during data upload
- What if my dataset is too large
- Guidelines for dataset-associated methodology documents
Data Sharing
- Can I choose who I share my dataset with in the community?
- Can I deny the use of my dataset in someone else's publication?
Data Publication
- How do I publish my dataset with ODC-SCI: Dataset Publication Checklist
- What is dataset publication and why publish with ODC-SCI?
- What is the ODC data review process and how long does it take to get a DOI?
- Minimal Dataset Standards for publication
- Common errors for Dataset and Data Dictionary
- What if I need to make changes to a published dataset?
- Can I delete my published dataset?
Other
- Do I need programming skills to submit, share, or publish the datasets?
- What happens to my dataset if I am no longer part of the lab/change labs?
- I have missing scroll bars while using the platform.
- How to get Additional Help
For tutorials and how-to guides for data formatting, uploading, and other ODC actions, click here to go to the Tutorials page.
An overview of the ODC-SCI
The Open Data Commons for Spinal Cord Injury is a cloud-based community-driven repository to store, share, and publish spinal cord injury research data.
There are several challenges for scientific reproducibility and bench-to-bedside translation. For example, only research and data that are published actually get disseminated, a phenomenon known as publication bias. Published research reflects to only a small fraction of all data collected, and data that do not lead to publication are largely ignored, hidden away in filing cabinets and hard drives. This results in an abundance of inaccessible scientific data known as “dark data”. Even when research is disseminated, it is usually in the form of summary reports of aggregated data (e.g. averages across individual subjects) such as scientific articles. The fact that the individual subject-level data are inaccessible further contributes to dark data.
The spinal cord injury (SCI) community created the ODC-SCI to mitigate dark data in SCI research. The ODC-SCI also aims to increase transparency with individual-level data, enhance collaboration, facilitate advanced analytics, and conform to increasing mandates by funders and publishers to make data accessible. Members of the ODC-SCI have access to a private digital lab space managed by the PI or multi-PIs for dataset storage and sharing. The PIs can share their labs’ datasets with the registered members of the ODC-SCI community and make their datasets public and citable. The ODC-SCI implements stewardship principles that scientific data be made FAIR (Findable, Accessible, Interoperable and Reusable) and has been widely adopted by the international SCI research community.
You can read more about the development of the ODC-SCI in our papers (Nielson et al., 2014; Ferguson et al., 2014; Callahan et al., 2017; Fouad et al., 2020).
Why share data with the ODC-SCI?
Sharing research is critical for scientific progress. Current approaches to data sharing in scientific communities primarily include direct sharing (i.e. via email) between individuals, upload of data as supplementary materials in a publication, or minimally-regulated sharing through personal websites or social media platforms. However, these options do not make the shared data FAIR: data is not readily findable, not broadly accessible, and almost never interoperable and reusable. The best way to publish data is using data repositories which offer capabilities specifically oriented to the goal of sharing data. The ODC-SCI is currently the only community-driven data repository for SCI research. This specific focus allows us to align the repository with FAIR data principles and the SCI community’s needs. Sharing data through the ODC-SCI unlocks latent potential in research data through FAIR principles, enabling the SCI community to better tackle its many challenges.
More directly, sharing and publishing data with the ODC-SCI can benefit you in a number of ways:
- Your data will all be organized in the same data format and be easily accessible and interpretable for you and your lab even in years to come.
- You will be ready when funders and journals expect you to publish all the data they funded/that are related to a manuscript.
- You will be able to compare your findings to those from other labs and use data from other labs to guide your own experiments.
- You will contribute towards reducing data bias and promote better research transparency.
What are the different account types on the ODC-SCI?
We have several different authentication steps and account types in the ODC-SCI to help protect unpublished data. You gain more access and functions as you are approved to the next account type.
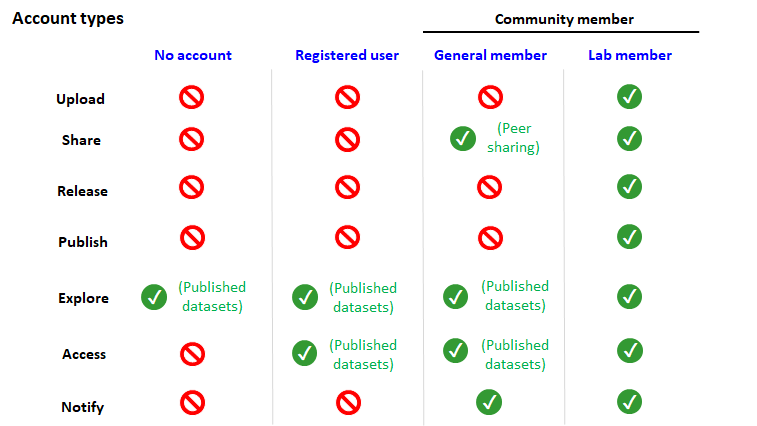
Registered User
Requirement: Email verification upon signing up
Functions: As a registered user, you can explore and access (download) published datasets.
General Member
Requirement:
- Be a Registered User
- Approval from ODC-SCI oversight committee
Functions: As a general member, other ODC-SCI members can directly share their datasets with you, including their unpublished datasets (feature under development).
Full Member
Requirement:
- Be a General Member
- Join/Create a lab - requires approval by the Principal Investigator (PI) of the lab on ODC-SCI OR requires approval from the ODC-SCI oversight committee if creating a new lab
Functions: As a full member, you will be able to upload, share, release, and publish your datasets. Additionally, you can explore and access unpublished datasets that have been released into the Community data space.
Why is there a need for all the different accounts?
We have several different authentication steps and therefore different account types in the ODC-SCI to help protect unpublished data. You gain more access and functions as you are approved to the next account type. For more information, please see “What are the different account types on the ODC-SCI?”
How does privacy and data protection work on the ODC-SCI?
There are several authentication steps and account types on the ODC-SCI to help protect unpublished data (see "What are the different account types on the ODC-SCI?" section). Additionally, the ODC-SCI is organized into different spaces that a dataset can belong to. Each space offers different levels of user access, and the movement of data from one space to another is always at the discretion of the lab’s PI. The general flow of data and the user access is as follows:
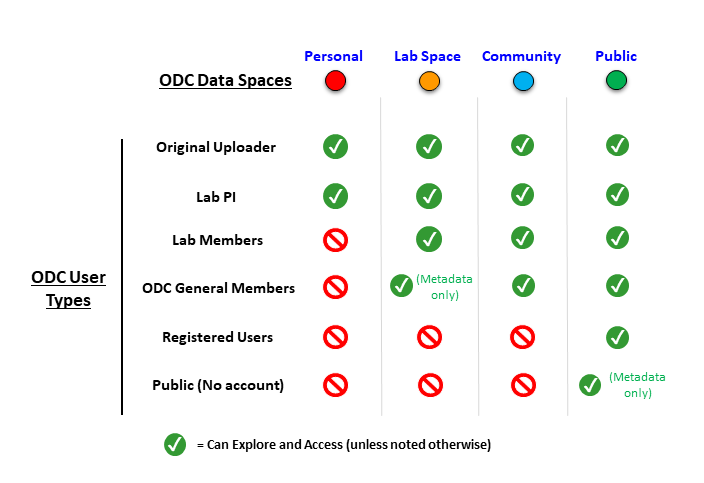
 Personal
PersonalA dataset is initially uploaded into the Personal space. Though the dataset must be uploaded into a specific lab, the dataset will only be visible to the original uploader and the lab’s PI.
 Lab Space
Lab SpaceThe PI can choose to Share a dataset with the rest of the Lab. Doing so moves a dataset from the Personal space to the Lab Space. Any dataset in the Lab space can be found and accessed by other Lab Members belonging to the same lab that the dataset was uploaded to.
 Community
CommunityThe PI can also choose to Release a dataset to the ODC-SCI Community space. Any dataset in the Community space can be found and accessed by General Members of the ODC-SCI, even if they do not belong to the same lab that the dataset was uploaded to. If you want to use a dataset in the Community space, you must adhere to the terms in the data use agreement.
 Public
PublicThe PI can initiate a DOI submission process to Publish a dataset into the Public space. If the submission is approved, a DOI will be generated for the dataset, and the dataset will be accessible to anyone with a registered account with the ODC-SCI. Datasets are published with an open source license - the Creative Commons Attribution License (CC-BY v4.0) - which allows anyone with access to use the contents of the dataset but sets the legal obligation of giving appropriate credit to the authors of the data. While only Registered Users of the ODC-SCI can access a published dataset, the metadata of the dataset will be findable and visible to anyone, even those without an account. Datasets in the Public space are fully considered accessible to the general public.
PIs control the full process
On the ODC-SCI, the PI has full control of their dataset up to the point of publication. The PI can move the dataset from Personal, Lab, and Community spaces as they wish. They can also publish a dataset from any data space at any time. Once a dataset is published and in the Public space, however, the published dataset can only be removed if the DOI is rescinded which will require an appeal to the ODC-SCI oversight committee.
What is FAIR data?
FAIR stands for Findable, Accessible, Interoperable and Reusable. FAIR establishes a framework for data sharing and defines a set of recommendations developed by FORCE11 (The Future of Research Communications and e-Scholarship) for successful data dissemination. FAIR data encompasses the principles of:
- Findable: data should be able to be found with enough explicit metadata to be searchable;
- Accessible: data should be accessible to others in some form;
- Interoperable: data should be able to integrate with other datasets of the same nature using structured formats and standard definitions such as common data elements;
- Reusable: data should include sufficient documentation and meet community standards in order to enable subsequent reuse of the data by others.
The ODC-SCI has been developed to follow the FAIR principles with tools and functionalities designed for the SCI community’s needs to ensure the success of data sharing with the ODC-SCI.
Is there a data quality check process?
Yes, in the ODC-SCI, the dataset, dataset metadata, and data dictionary undergo quality checks for proper formatting and completeness. The checks ensure that the data is Interoperable and Reusable. Some quality checks are performed during the upload of the dataset, ensuring a minimal level of quality to all private and public datasets in the ODC-SCI. The check during the upload process is automatic without human oversight since the upload is handled privately within the user’s account. When data is released to the Community data space or submitted for publication, further checks will be conducted by the ODC-SCI Data Team to ensure that the released or published dataset meets FAIR standards.
Who can upload data on ODC-SCI?
Any registered lab member can upload data to the ODC-SCI lab they belong in. The PI or any lab members they designate (as lab managers on the ODC-SCI) can share, release, and publish datasets. For more information, see: “What are the different account types on the ODC-SCI?”
What type of data is accepted?
Any Spinal Cord Injury (SCI) associated data from independent species that can be disseminated in a spreadsheet (csv) format is accepted. This includes in vivo and in vitro data. Human data must be de-identified prior to upload to the ODC-SCI.
Should I upload and publish raw data or analyzed data?
We encourage publishing primary data: minimally processed data that provides the most flexibility and usefulness for additional analysis. Importantly, primary data is not always raw data but may have some minimal transformation to make the data more directly usable.
If the data has been processed, we recommend explaining the methodology in a dataset-associated methodology document which you can upload alongside the dataset.
Do I have to format my data for upload?
Yes. Before uploading a dataset to the ODC-SCI, your dataset must be formatted into a Tidy data format.
See: “ODC data structure: Tidy data format” for more information.
See: “How to prepare/format data for uploading” for step-by-step instructions.
ODC data structure: Tidy data format
This section provides additional information about the concept of Tidy data. Click here for specific instructions on how to prepare and format your data for upload to the ODC.
Data structured for upload to the ODC must follow a specific format known as the Tidy format. The format was developed as a data structure to facilitate big data analytics and standardize the way data values are organized across datasets even across different disciplines and origins. The implementation of the Tidy format has significantly reduced the time scientists spend reformatting data, facilitated the ease of data exploration and analysis, and streamlined the development of analytical tools. Furthermore, the standardized data structure ultimately promotes FAIR data sharing (Findable, Accessible, Interoperable, and Reusable) by improving the Interoperability of the data.
Importantly, Tidy data can look quite different from data formatted for human readability. A Tidy dataset is organized with:
- Columns representing Variables (e.g. experiment parameters, measured outcomes)
- First row containing the Variable names
- All other rows representing Observations
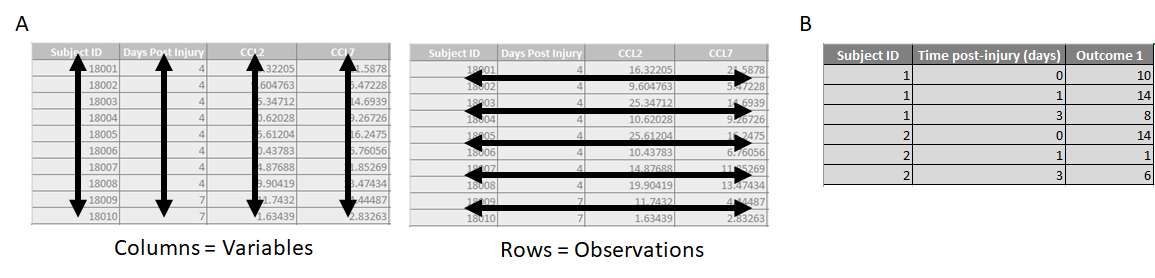
(A) Visual reference for Variables and Observations. (B) An example where the same subject can have multiple rows (i.e. Observations).
For specific instructions on how to prepare and format your dataset into a Tidy format for upload to the ODC, click here. The instructions also provide guidelines for combinations of parameters that define an Observation. If you need additional guidance, feel free to contact our help desk and an ODC Data Wrangler can assist you.
What is a Data Dictionary?
A data dictionary is a file containing information about each Variable (i.e. Column) in the dataset. The data dictionary provides critical information for the interpretability and reusability of the dataset. Importantly, the data dictionary helps other users understand what each of your Variables are and any important details you include. We encourage you to submit a data dictionary with your dataset, even if you do not plan to publish the data.
For more details and a downloadable Data Dictionary template, please see “How to prepare a data dictionary (Data Dictionary Guidelines)”.
What is a CSV file format?
“CSV” (or ".csv") is a widely-used file format for spreadsheet-style datasets and stands for “comma-separated values”. In brief, a CSV is a delimited text file where each value (i.e. cell of the spreadsheet) is separated by a comma.
We require datasets and data dictionaries to be CSV files when you are uploading to the ODC-SCI. You can easily convert excel (e.g. ".xls", ".xlsx") files to “.csv” files through spreadsheet programs like Excel by saving as a ".csv".
Importantly, the process will only save the ACTIVE spreadsheet in your excel file. The process will also exclude any graphs or graphics since the CSV file will only include the values in the spreadsheet cells. For more information about how to format your dataset, see the “How to prepare/format data for uploading” section in the Tutorials..
Common errors during data upload
Dataset Upload Errors
There are a few common errors that are flagged during the data upload process. If you hit an error on the data preview page after selecting your datafile, check your dataset for the following errors:
- Your datafile is not a .csv file. For more information, see "What is a CSV".
- Your datafile contains a column with an empty header (i.e. missing a value in the first row). You might have forgotten to type a name for a column or have an empty column in the middle of your dataset. Make sure every column of your dataset has a column name in the first row.
- Your datafile contains duplicate header names. Make sure every column must have a unique column header.
- One of your column headers has a variable name that is longer than 64 characters. There is a 64 character limit for the column headers; make sure every header is 64 characters or less.
- You used a comma in your datafile, and the .csv file is reading the comma as a separator between one entry and the next. This can be a source of error for header names and data entries. If this is the error, you will find rows that have different numbers of columns and/or entries that have been shifted to other columns.
- You can fix this error by removing commas from the entries in your datafile.
- A second way to fix this is to open your .csv in a spreadsheet software like Excel, correct for any shifted cells, and save as a new .csv through the program. Many software programs will naturally treat cells with commas as a fixed sequence of characters and won't treat those within-cell commas as separators between cells. This treatment will be maintained when you upload the new .csv to the ODC-SCI.
- Your datafile might be too large. If your dataset is larger than 100Mb or has a total number of cells larger than 3,000,000, see the next section "What if my dataset is too large".
For more information about how to prepare your data for upload, see the "How to prepare/format data for uploading" Tutorial.
Data Dictionary Upload Errors
When uploading a data dictionary file, there are a few possible errors that are flagged during the data dictionary upload process. You will be notified directly on the upload page; as a reference, the possible errors include:
- Your data dictionary is not a .csv file. The data dictionary must be a .csv file for upload.
- Your data dictionary is missing a column. The data dictionary must include all 9 required columns with exact spelling.
- Your data dictionary does not include an entry for every column of your dataset. Every Variable (i.e. column header) in your dataset must have a respective row in your data dictionary.
- While not an error, if you have rows in your data dictionary that are missing values under Title or Description, this will flag a warning. This is not required for initial data dictionary upload, but during DOI request/dataset publication, we require that every row in your data dictionary have at least VariableName, Title, and Description columns filled out.
For more information on how to prepare your data dictionary for upload, see the "How to Prepare a Data Dictionary" Tutorial.
If you cannot identify the error in your dataset or data dictionary, please contact the ODC Data Team (data@odc-sci.org) for guidance.
What if my dataset is too large
If your dataset is too large (e.g. your dataset is larger than 100Mb or has a total number of cells larger than 3,000,000), it can cause an error during the data upload process. The error can also happen when you are trying to replace your dataset using the Upload New Version workflow. In both cases, we recommend splitting up your dataset-to-be-uploaded into chunks with fewer rows and utilizing the Append Data workflow to add your dataset piece by piece. For a detailed tutorial of the Append Data workflow, see "How to append new rows to a dataset" in the Tutorials.
Importantly, every chunk of your dataset must have the same column headers in the first row of each csv file. Make sure you (1) split your dataset along the rows and not along the columns and (2) include the column headers in every file.
If you have any difficulties, please contact the ODC Data Team (data@odc-sci.org) for guidance..
Guidelines for dataset-associated methodology documents
Currently, we do not require methodology documents for you to upload and publish your datasets. However, we do encourage you to include them as they improve the interpretability and reusability of your data.
Some recommendations for compiling a methodology document:
- If the dataset comes from a published paper (and hence has the methodology already published), you can provide the paper citation and link as part of the Methodology doc/pdf. Due to potential copyright issues, do not copy/paste the methods from any published papers.
- If you have multiple protocols you wish to upload for the to the same dataset, we recommend combining them all into a single word document or pdf. The ODC-SCI only allows a single Methodology file to be attached to each dataset.
Can I deny the use of my dataset in someone else’s publication?
Yes, as long as the dataset has not been published with an assigned DOI. Once a dataset has a DOI and has been published (i.e. moved to the Public Space), the use of the dataset falls under the Creative Commons Attribution License (CC-BY v4.0), which allows anyone with access to use the contents of the dataset but sets the legal obligation of giving appropriate credit to the authors of the data.
How do I publish my dataset with ODC-SCI: Dataset Publication Checklist
Pre-submission Checklist
Before you submit your dataset for publication/DOI request, make sure your dataset meets the following minimum requirements:
- The Dataset is properly formatted in the Tidy data format
- In brief:
- The dataset should contain a single data table (instead of multiple data tables on the same spreadsheet)
- Each column corresponds to a single Variable (e.g. Subject_ID, Injury_group, biomarker_measure_1, etc)
- The first row contains the Variable names (i.e. column headers)
- Each consequent row is an observation
- The dataset contains the Minimal Set of Variables (See: "Minimal Dataset Standards for publication")
- See also: "ODC data structure: Tidy data format" and "How to prepare/format data for uploading"
- In brief:
- The dataset Metadata is complete and reflects the dataset
- On the dataset metadata editor, you must:
- Have a Title
- Fill in the Abstract fields
- Have at least one contact author
- Provide funding sources as needed.
- Provide additional authors, contributors, and data provenance as needed.
- See: "Metadata Editor Tutorial" and "Minimal Dataset Standards for publication"
- On the dataset metadata editor, you must:
- The Data Dictionary is complete and sufficient
- Your data dictionary must:
- Have all 9 required data dictionary columns
- Have a row/entry corresponding to each column of your dataset (i.e. every dataset column name appears under the VariableName data dictionary column)
- Fill the VariableName, Title, and Description columns for every row/entry
- Additional information for each row/entry should be filled in as needed
- See: "What is a Data Dictionary?", "How to Prepare a Data Dictionary", and "Minimal Dataset Standards for publication"
- Your data dictionary must:
Request DOI/Publication
To request a DOI/publication for a dataset, you must be logged in as the PI of the lab that has the dataset. Only ODC-SCI lab PIs have the authority to request DOI/dataset publication.
If you are logged in as the PI:
- Navigate to the "Current Lab" page using the left hand navigation menu.
- Find the dataset in the Datasets window.
- Click on the dataset status for the dataset.
- Click on the "Request DOI Form" button.
- Fill out the request DOI form (if relevant), confirm you understand and agree to the data review policy, and click on the "Submit DOI Request" button.
For images of the process, refer to the "How to Share/Release/Request to Publish a Dataset" tutorial section.
Once you have completed the process, the dataset status should change to "DOI request". The ODC-SCI Editorial Board and Data Team will be automatically notified to initiate the dataset review process. We will work with you through the review process to ensure that the dataset meets the FAIR principles and data standards established by the ODC-SCI.
The process may take a few weeks depending on the revisions required. For more information, see “What is the ODC data review process and how long does it take to get a DOI?”
What is dataset publication and why publish with ODC-SCI?
Dataset publication is the process of making your data accessible to the general public. There are several good reasons to make your research data public. Publishing your data makes the data accessible to more people, which can mitigate issues of reproducibility. Dataset publication also increases the transparency of your research process and increases visibility of your work. Providing access to your data allows for modern forms of meta-analysis at the individual subject level (instead of meta-analysis of summarized data, which is what is typically published in academic journals), which can contribute to new discoveries while minimizing repetitive experiments and unnecessary waste of resources. Finally, there is an ongoing cultural shift with publishers and funding agencies mandating public release of data in order to publish a research article or to get funded. The ODC-SCI provides the foundation and materials to familiarize yourself with the process and offers the infrastructure to take your own data from private storage to the public space.
In the ODC-SCI, data stewards (i.e. PIs) can start the process of publishing data whenever they decide a dataset is ready to be released to the public. At the end of this process, the dataset and related documentation will be accessible to any registered user of the ODC-SCI. A digital object identifier (DOI) will be associated with the dataset, and a citation will be generated so the public dataset can be cited much like a published article. ODC-SCI uses DataCite to generate the DOI and the citation. Datasets are published with an open source license, the Creative Commons Attribution License (CC-BY v4.0), which allows anyone with access to use the contents of the dataset but sets the legal obligation of giving appropriate credit to the authors of the data.
See our "Minimal Dataset Standards for publication" for more information on dataset and metadata quality requirements.
What is the ODC data review process and how long does it take to get a DOI?
Once uploaded, data can move quickly through the ODC-SCI data spaces at the PI’s discretion between Personal, Lab, and Community data spaces (see: “How does privacy and data protection work on the ODC-SCI?”).
The final publishing step involves a two-step review process by the ODC-SCI Editorial Board and Data Team. The length of the review process depends on various factors including:
- Whether the Dataset is within the scope of ODC-SCI
- Dataset formatting
- Completeness of the dataset metadata
- Completeness of dataset-associated documents (i.e. data dictionary).
Summary of review process
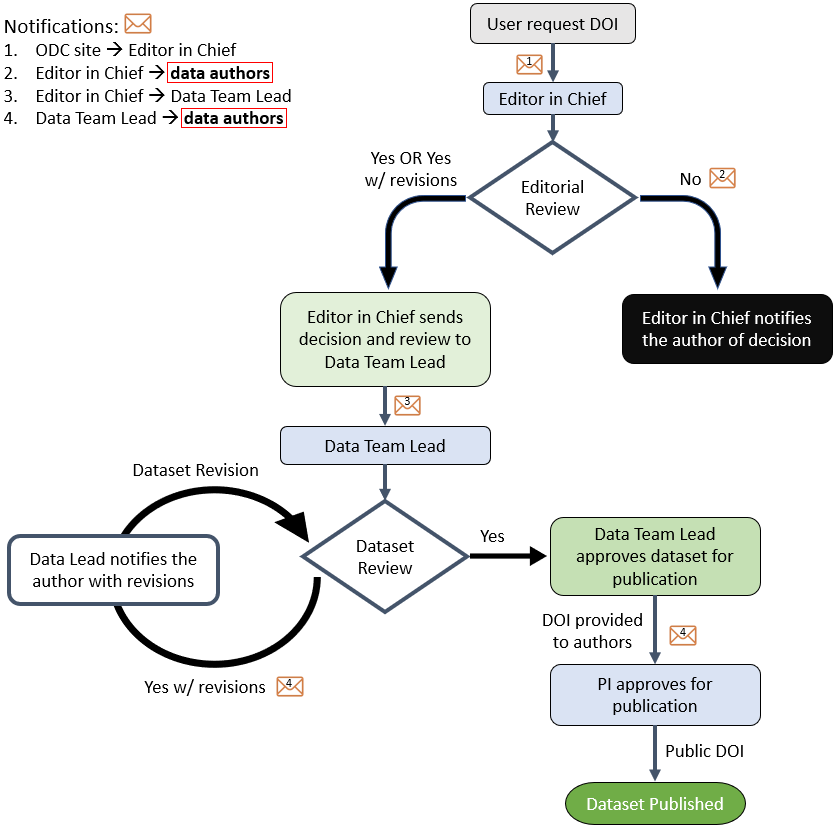
Editorial Review
Your dataset will first be sent to ODC-SCI editors to determine whether the content is appropriate and within the scope of ODC-SCI. You will be contacted by the Editor in Chief within 3-5 business days if the editors have any concerns regarding your dataset.
If the Editorial Board decides that your dataset fits within the scope of the ODC-SCI, the dataset and any comments from the editors will be sent to the ODC-SCI Data Team for the dataset review process.
Dataset Review
The ODC-SCI Data Team will review your dataset, metadata, and data dictionary to ensure the formatting and contents conform to the ODC-SCI data structure and meet the minimum dataset standards for publication. The ODC-SCI Data Team will will contact you if any revisions are required.
The full dataset publication process can take a few weeks depending on the revision process. You can track any changes to the status of your publication/DOI request on the Current Lab page as a PI/Lab Manager.
Final PI Approval
Once the dataset is fully approved by both the Editorial Board and Data Team, the DOI will be reserved and the corresponding PI will be notified. The PI has control over the last step of the publication process: final approval for publishing the dataset and the associated landing page. Once the PI approves, the landing page and dataset will be made public and accessible to all ODC-SCI registered users within 24 hours. The dataset DOI will be accessible on the published landing page.
The final approval button can be found on the Current Lab page as a PI/Lab Manager in the Dataset window once the dataset has completed the ODC-SCI review process.
If you have questions about or during the process, please contact the Data Team at data@odc-sci.org.
Minimal Dataset Standards for publication
The following are standards/requirements for the dataset, dataset-associated metadata, and dataset-associated data dictionary that will be assessed by the Editorial Board and Data Team review process during dataset publication/DOI request.
Dataset Standards:
Dataset formatting
The ODC-SCI requieres a minimal set of formatting standards for publicaiton. We recomend you check these:
How to prepare/format data for uploading
Common errors for Dataset and Data Dictionary
Minimal Set of Variables
Datasets submitted for publication on the ODC-SCI must include the following variables (i.e. columns).
We recommend downloading the data dictionary template (click here to download) which has the definitions and information for each column. The template will also help you get started in compiling your data dictionary, which will be required for dataset publication/DOI request.
If a required variable/column is not relevant to your dataset or you are missing data for the entire column, you must still include the column. Fill in the values with "not available", "not applicable", or "unknown" as appropriate for your case.
The columns should use these exact names:
- Subject_ID: Unique identifiers for each subject in the dataset
- Species: Species of the subject
- Strain: Strain of the subject
- Animal_origin: Vendor or origin of the animal
- Age: Age of the subject at start of experiment. If age is available at different timepoints, age is provided at the corresponding time in a corresponding time/timepoint variable
- Weight: Weight of the subject at start of experiment. If weight is available at different timepoints, weight is provided at the corresponding time in a corresponding time/timepoint variable
- Sex: Sex of the subject
- Group: Name or identifier of the experimental group at which the subject was included if any
- Laboratory: Name of laboratory, usually the PI
- StudyLeader: Name of person responsible for overseeing project
- Published: General category of whether the study was published/in press, under review/pre-press, or unpublished.
- Exclusion_in_origin_study: Whether the subject was included in the study that originated the data. 'Total exclusion" if excluded from the entire study, otherwise, specify experiment or measures of which the animal was excluded if any. For example: animals that were run in behavior but maybe tissue is loss and excluded from histological analyses. Reasons forexclusion might be specify in the exclusion_reason variable.
- Exclusion_reason: Reason by which the subject was excluded from the study that originated the data as specified in the Exclusion_in_origin_study variable
- Cause_of_Death: Cause of death (e.g. perfusion/necropsy, died during surgery, euthanized for health reasons, etc)
- Injury_type: Type or model of injury used in the subject (e.g. contusion, complete transaction, partial section)
- Injury_device: Name of the device used for the injury
- Injury_level: Spinal cord level at which the injury was performed including segment (e.g. cervical; C) and number (e.g. C5)
- Injury_details: Other details referent to the injury that might be relevant to understand the severity and type of injury performed
Metadata Standards
For instructions on the Metadata Editor, see the "Metadata Editor Tutorial" tutorial section.
Metadata is critical so users can understand key details about the data. Metadata also improves how easily searchable the dataset will be. In general: the more metadata, the better. This section provides definitions, checklists, and recommendations applied during the revision of the metadata information. The checklists are designed to help users prepare their data and describe items to be reviewed by the ODC-SCI Editorial Board and Data Team to help improve the reusability of the data.
Dataset Publication Title
The published dataset title will be the first information a user sees when accessing a dataset. A good title of a dataset, like a good title for a research paper, should tell the reader why they should be interested in this particular data, providing information about the content of the dataset. The title should also provide key details that will enable effective retrieval by a search engine. In many search engines, the title is weighted very highly in ranking search results, so it is important to give the title careful thought.
- Does the title inform the user of key details about the data? (Injury method, species, sex, outcome measures, etc.)
- Will it be helpful for users trying to search for the data?
Dos and Don'ts:
- Do include information like injury method, technique used, species, purpose, sex, etc.
- Do Not include abbreviations for entities like anatomical regions.
- Do Not include the lab name or grant number.
- Do Not use the same title of an associated paper. If the dataset has a scientific paper associated to it, avoid using the same title. Datasets and scientific papers are separate entities. The title for a dataset should describe the content of the data, while the title of a paper usually describes the conclusions of a study. The provenounce/originating publication section of the metadata provides a space to link the dataset to associated publications.
- Cervical (C5), unilateral spinal cord injury with diverse injury modalities, multiple behavioral outcomes, and histopathology (https://scicrunch.org/odc-sci/about/odc-sci_26)
- Repeated measurements of hindlimb CatWalk variables in normal rats (https://scicrunch.org/odc-sci/about/odc-sci_432)
Abstract
The structured abstract provides a description of the dataset. Abstracts for datasets are a short description of the content of the dataset that allows readers to understand the origin of the data, the reason the data was generated, and lets the user know important details about the dataset. This allows users to make an informed decision about whether to use the data or explore them further. Abstracts must have three sections:
- Study purpose: Short description of the reasons (i.e. the scientific question) for data collection. Answers these questions:
- Why was the data obtained?
- What was the study designed to do?
- Data collected: Description of the content of the dataset. That might include relevant information such as describing experimental groups, injury models, sample size, measured variables, etc. Answers these questions:
- What data are available?
- How were they obtained?
- How many conditions are represented?
- Is this a stand-alone dataset or part of a larger study?
- How many modalities?
- What can the data be used for?
- Conclusion: The conclusion informs the reader of the findings and interpretations from the authors about the data. This helps with understanding the analysis conducted on the data. If no conclusions were drawn, enter "not applicable". Answers this questions:
- What was learned from this study?
Tips: Think about whether your description would pass reviewers if you submitted it as an abstract for a manuscript. Would a reviewer accept a one line description of what you did? e.g., testing BBB score in SCI animals treated with X. The more detail you provide, the more useful the data will be. However, remember, that you are describing a dataset, not a scientific publication. After reading the description, would a reader understand what they are looking at when browsing or downloading your data?
Keywords
Short list of concepts that identifies the dataset.
- Does the keywords provide key information about the topic of the data?
- Will it be helpful for users trying to search for the data?
Provenance/Originating publications
On occasion, datasets are collected from different sources or are part of already published research. This section allows data authors to specify the related sources of information for a given dataset in order to track the provenance of the data and to point to important sources of information that can help with data reusability. For each element, authors should specify the source (e.g. the citation of a paper) and a short explanation of the relationship of the dataset with the source.
- Are these data part of a manuscript that has been submitted?
Tips: Think about referencing citations in a paper. In a paper, if you want to direct readers to further information not provided in the text, you make a citation. Here, would it be relevant for the user to know of other information that relates to the data?
Notes
Notes give authors space to explain further information that can be relevant for future data users to know. For example, if some caution should be taken when considering parts of the data.
Funding and acknowledgements
As much as in a research article, authors should specify the list of funding that made the dataset possible and other acknowledgements.
Contributors/Authors
The list of the authors of the dataset is similar to authors in a research article. Authors might be the same authors of a related publication if applicable. Authors must be part of the list of contributors, but not all contributors might be considered authors (see below). For each author, the affiliation and the ORCID (if available) will be needed.
- Do all data authors have an ORCID ID?
- Do all data authors have an affiliation?
- Is the contact information present?
Note about ORCID IDs: The ORCID is required for the PI and primary contact person of the dataset will be required. This will ensure users will know the correct individuals to contact regarding the dataset. Additionally, the ORCID ID ensures that contributors get credit for publishing the data. Registering for an ORCID ID is easy at https://orcid.org/. If you have students, postdocs, or developers, we really encourage you to get them to sign up for an ORCID ID as they will use it throughout their career.
Contributors are the personnel that made the dataset possible. This includes the authors of the dataset but might also include other important contributors such as data collectors, data managers, analysts, collaborators, administrative personnel, etc. This gives the opportunity to credit others beyond the main authors. For each contributor, the affiliation and the ORCID (if available) will be needed.
- Do all data contributors have an ORCID ID?
- Do all data contributors have an affiliation?
Data Dictionary Standards
At the time of submission, the data dictionary must meet the following standards:
- Every column of your dataset must have a corresponding entry (i.e. row) in the data dictionary. I.e. all column headers of your dataset must appear in the VariableName column of the data dictionary.
- Every entry in the data dictionary must have the following columns filled: VariableName, Title, Description, DataType. The other columns should be filled as appropriate.
For full instructions on compiling a data dictionary, see the "How to Prepare a Data Dictionary" tutorial.
Common errors for Dataset and Data Dictionary
In ODC-SCI, the dataset and the data dictionary undergo quality checks for proper formatting (based on goodTables framework). These checks ensure that the data is Interoperable and Reusable with other datasets. Some of the quality checks are performed during the uploading of datasets, ensuring a minimal level of quality to all private and public datasets in the ODC-SCI. The check during the upload process is automatic without human oversight since data upload is handled privately within the account of the data owner. When data is released to the Community data space or submitted for publication, further checks will be conducted to ensure that the released or published dataset meets FAIR standards:
- Source errors (Checked at upload): ODC-SCI can not read the data file. Possible reasons include:
- The data file is not a *.csv. The ODC only accepts upload of *.csv data files.
- Reserved special characters were used in the column headers (first row with the variable names). Check our recommendations for How to upload data.
- Structure errors:
- Blank-header (Checked at upload): There is a blank variable name. All cells in the header row (first row) must have a value.
- Duplicate-header (Checked at upload): There are multiple columns with the same name. All column names must be unique.
- Blank-row (Checked at upload): Rows must have at least one non-blank cell.
- Duplicate-row: Rows can not be duplicated.
- Schema errors: In ODC-SCI the schema is marked by the data dictionary. These errors reflect conflicts between the data dictionary and the dataset.
- Extra-header: The dataset contains at least one variable name not defined in the data dictionary.
- Missing-header: The dataset is missing at least one variable name defined in the data dictionary.
- Missing-definition: The definition of a variable in the data dictionary is missing.
- Required-constraint (Checked at upload): A required field for the dataset contains no values or is not assigned on the dataset. Currently the only required value in the datasets is the subject identifier. As ODC-SCI develops additional data standards, it is possible that more variables will be required on all datasets.
- Value-constraint: The values of a variable should be equal to one of the permitted values enumerated in the data dictionary, or within the limits of the permitted values.
What if I need to make changes to a published dataset?
PIs can request permission to make changes/updates to published datasets from their lab. In order to maintain proper data provenance, if a published dataset needs to be edited, please contact the ODC SCI Data Team (data@odc-sci.org) with an explanation of the changes you wish to make. The Data Team will assess the proposed changes on a case-by-case basis to inform you of how the changes will be applied and guide you through the process.
For more information, refer to the ODC-SCI Version Control Policy.
Can I delete my published dataset?
Once a DOI and landing page have been published to the public on the ODC-SCI, we will not delete the information. However, PIs can ask for the dataset and associated data dictionary and supplementary files to be retracted. To initiate the process, please contact the ODC SCI Data Team (data@odc-sci.org) with an explanation of why the dataset needs to be retracted. The Data Team will assess the request and help you through the process.
For more information, refer to the ODC-SCI Version Control Policy.
Do I need programming skills to submit, share, or publish the datasets?
No. No programming experience is required in order to upload your dataset. You can format your dataset in any spreadsheet software before uploading, and all the steps of the process are handled directly on the website.
In case you need assistance with anything during the process, you can contact us via the Help Desk button on the bottom right of every page or by emailing us (info@odc-sci.org).
What happens to my dataset if I am no longer part of the lab/change labs?
The dataset that you upload is property of the lab, and the PI of the original lab will maintain full control of the dataset on the ODC-SCI.
I have missing scroll bars while using the platform.
If you are using a Mac, some of the scroll bars on the platform (e.g. in windows listing available datasets or lab members) might not show up for you because of your computer settings. For example:
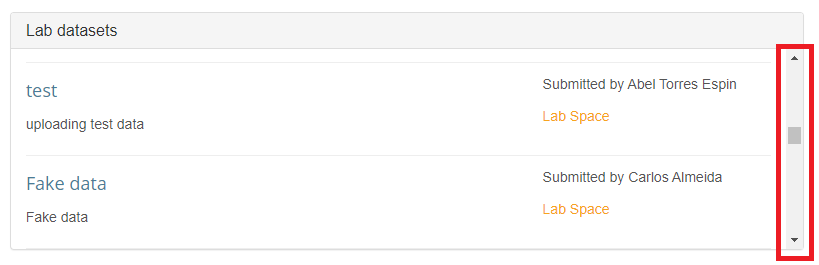
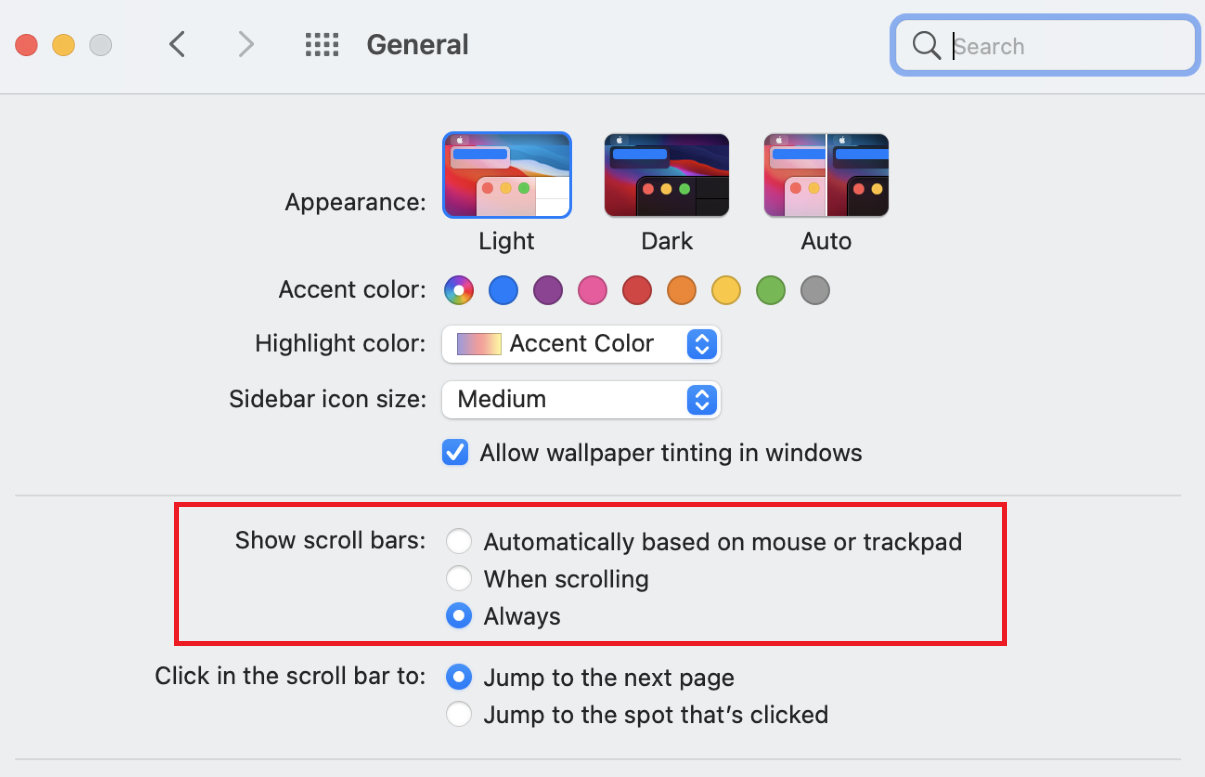
To fix this issue:
- Go to the General settings of your Mac.
- Find the "Show scroll bars" option.
- Change the setting to "Always".
How to get Additional Help
Help Desk
If you can’t find a relevant help section for the page you’re on or need to report a bug, you can contact our help desk via the “Contact help desk” button at the bottom of every page. The button will automatically inform us of which page you are on when you contacted the help desk.
Contact Help Desk is at the bottom right of every page.
If you are reporting a bug, please also include the following information:
- Operating System
- Browser/Version
- Steps you took leading up to error
Please allow 2-3 business days for a response.
General Contact
If you cannot find a relevant help or FAQ section for your question, you can email us at: info@odc-sci.org.
Please allow 2-3 business days for a response.
About
Spinal cord injury (SCI) produces a complex syndrome characterized by loss of motor control and mobility; loss of bladder, bowel and sexual function; pathological pain; and loss of autonomy. The multifaceted nature of SCI presents a challenge for the translational pipeline. This problem of SCI complexity can be conceptualized as a big-data issue: the field needs a forum for large-scale data-sharing and application of advanced analytics to catalyze SCI discoveries. Various funders and publishers have recognized this need as well currently implementing data sharing mandates.
To address this challenge the SCI research community is assembling a large database through collaborative and FAIR data sharing. We are a digital infrastructure with the goal to democratize SCI data, allowing researchers to access existing SCI data, contribute their own, and publish with citable DOI. Learn more
Contact Us
Use the Contact help desk button on the right bottom corner of your screen.
Send us an email at info@odc-sci.org. Please allow 2-3 business days for a response.